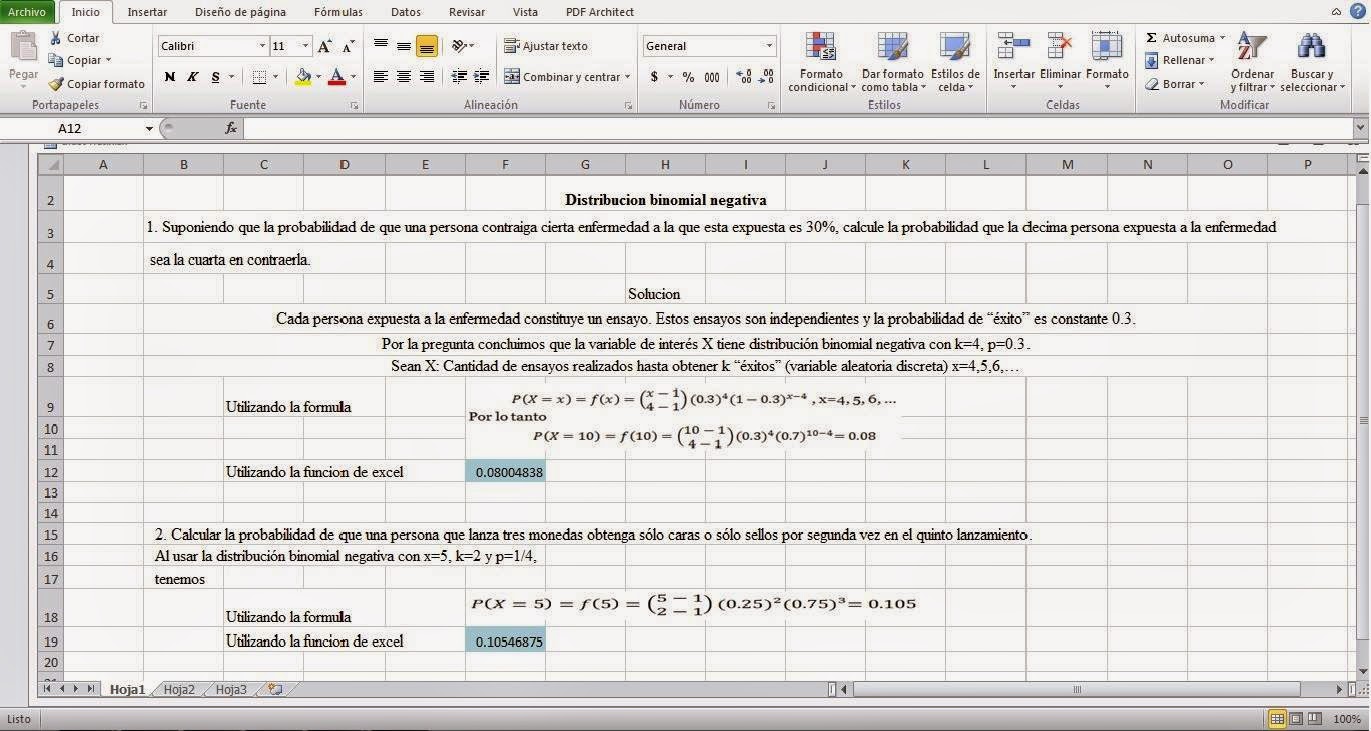
Ejemplo.
El departamento de queja de McFarland Insurance Company informa que el costo medio para tramitar una queja es de $60. Una comparación en la industria demostró que esta cantidad es mayor que en la demás de compañías de seguros, así que la compañía tomo medidas para reducir gastos. Para evaluar el efecto de las medidas de reducción de gastos, el supervisor del departamento de quejas selecciono una muestra aleatoria de 26 que el mes pasado.La información de la muestra aparece a continuación.
$45
|
$49|
|
$62|
|
$40
|
$43
|
$61
|
48
|
53
|
67
|
63
|
78
|
64
|
48
|
54
|
51
|
56
|
63
|
69
|
58
|
51
|
58
|
59
|
56
|
57
|
38
|
76
|
|
|
|
|
Es razonable concluir que el costo medio de atención de una queja ahora es menor a $60 con un nivel de significancia de 0.01?
Aplique la prueba de hipótesis con el procedimiento de 5 pasos.
Paso 1.
La prueba es de una cola, pues desea determinar si hubo una reducción en el costo. La desigualdad de la hipótesis alternativa señala la región de rechazo en la cola izquierda de la distribución.
Paso 2.
El nivel de significancia es 0.01
Paso 3.
El estadístico de la prueba es la distribución t porque resulta razonable concluir que la distribución del costo por queja sigue la distribución normal.
No se conoce la desviación estándar de la población, por lo que esta se sustituye por la desviación estándar de la muestra. El valor del estadístico de la prueba se calcula por medio de la formula.
Paso 4.
Los valores críticos de t aparecen en el apéndice b2 una parte del cual se produce en la tabla 10-1.La columna extrema izquierda de la tabla esta rotulada como gl, que representa los grados de libertad. El numero de grados de libertad es el total de observaciones incluidas en la muestra menos el numero de poblaciones muestreadas, lo cual se escribe n-1. Aquí el numero de observaciones de la muestra es de 26, y se muestrea una población, asi que hay 26-1-25 grados de libertad.
El costo medio por queja de la muestra de 26 observaciones es de $56.42. La desviación estándar de esta muestra es de $10.04. A sustituir estos valores en la formula de t obtenemos.
Paso 5.
Como el -1.818 se localiza en la región ubicada a la derecha del valor critico de -2.485, la Hipótesis nula no se rechaza con el nivel de significancia de 0.01. No se demostró que las medidas de reducción de costos hayan ajado el costo medio por queja a menos de $60.Es decir, la diferencia de $3.58 ($56.52-$60) entre la media muestral y la media poblacional puede deberse al error de muestreo.
Ejemplo 2.
Suponga que se está interesado en determinar si hay evidencia que el aumento de peso promedio de unos animales a los dos meses de aplicar una determinada dieta es de 20Kg. Se conoce que el aumento de peso sigue una distribución normal con varianza σ2=4kg
Primer paso:
Se tienen las siguientes hipótesis.
H0=20 y H1≠20
Segundo paso:
El nivel de significancia o probabilidad de cometer un error Tipo I en esta prueba sería alfa=0.05
Se tomará una muestra de n=10 animales. Los datos son:
16.5
16.4
18.5
19.5
20.2
21.0
18.5
19.3
19.8
20.3
Tercer paso
Puesto que se conoce la varianza poblacional, la prueba estadística a utilizar es la prueba Z:
Cuarto paso graficamos el resultado.
Los valores críticos se determinan buscando en la tabla de distribución normal estándar acumulada el valor zde para un área de 0.025, el valor obtenido es z1=-1.96, el valor de z2 será el mismo z2=1.96, luego la regla de decisión para la hipótesis será no rechazar H0 si -1.96 zc 1.96
Quinto paso
Como la media muestral es 19, y la media de la población es 20 y se tiene que n=10, entonces el valor de la estadística de prueba zc está dado por:
Se compara el valor calculado de la prueba con los valores críticos (obtenidos de la tabla de distribución normal estándar), para determinar si cae en la región de rechazo o de no rechazo. En este caso zc=-1.58. Se encuentra dentro de la región de no rechazo. En este caso no se rechaza la hipótesis nula.
Ejercicio 20.
Hugger Polls afirma que un agente realiza una media de 53 entrevistas extensas a domicilio a la semana. Se introdujo un nuevo formulario para las entrevistas, y Hugger desea evaluar su eficacia. La cantidad de entrevistas extensas por semana de una muestra aleatoria de agentes es:
53 57 50 55 58 54 60 52 59 62 60 60 51 59 56
Con un nivel de significancia de 0.05, ¿puede concluir que la cantidad media de entrevistas de los agentes es más de 53 a la semana?
H0<= 53 H1>53
Ya que el nivel de significancia de 0.05 se tiene que revisar en la tabla t student con un grado de libertad de 14, donde obtenemos 2.14, es decir si el valor de t calculado es menor a -2.14 la hipotesis nula se rechazara.
Encontramos el valor de la desviacion de la muestra y de la media de la muestra
obtenemos la media de la muestra
(53 + 57 + 50 + 55 + 58 + 54 + 60 + 52 + 59 + 62 + 60 + 60 + 51 + 59 + 56)/15
= 56.4
Despues la desviacion de la muestra se calcula siguiendo la regla de sumatoria de la raiz de ((Xi - 56.4)^2/14)=12.72
Obtenemos el valor de t donde tenemos que t=(x-μ)/(s/raiz(n-1))
por lo tanto t=(56.4-53)/(12.72/raiz(14)) siendo t= 1.000
Es decir nuestro 1 se encuentra dentro del intervalo donde se acepta H0,
por lo tanto la cantidad de entrevistas no es mayor a 53